Latest videos

▬▬ Liens Utiles ▬▬
► Me suivre sur FB : https://www.facebook.com/TutoInfoFR/
Merci d'avoir regardé ce Tutoriel !
----------------------------------------------------
© Tutoriels Informatiques FR - 2020

in this video I go over how to generate snippets of python code using open AI's gpt-3 playground. It's surprisingly good at generating programs that you describe with natural language. This is perfect for rapid prototyping and testing new features. I've linked the playground below so you can try generating python for yourself!
https://beta.openai.com/playground
Song: Wiguez & EH!DE - The Path (Ft. Agassi) [NCS Release]
Music provided by NoCopyrightSounds
Free Download/Stream: http://NCS.io/ThePath
Watch: http://youtu.be/

In this quick tutorial we will download and install the Open AI GPT-2 Model and then generate a text based on some input. Basically we will use the Open AI model to build a basic AI Text generator. You can fine tune this for certain tasks like AI Generated Code, Music, Text and so on but in this example we will be generating text based on some input. Also keep in mind this is not some text from the training set or from a website, the AI generates it's own unique response.
In order to get Open AI GPT-2 up and running you need to download the model from the Github repository, install the requirements, download the models and run the sample. You can also fine tune the GPT-2 NLP for other categories in order to make it much more accurate.
If you want me to create an app around this or create a video where I am fine-tuning the model leave a comment down below. If enough people are interested I will create video about that!
🚨Subscribe to my Tech and Software Newsletter🚨 Everything around Tech and Software Development from tutorials to latest news, tips and tricks. Learn everything from creating Ads to configuring your own cloud infrastructure! Use: 🚨 https://noveltechmedia.com 🚨
For any thoughts, ideas, feedback or questions contact me at
🚨 [email protected] 🚨.
Disclaimer:
All videos are for educational purposes and use them wisely. Any video might have inaccurate or outdated information. I give my best to research every topic thoroughly but please be aware that videos can contain mistakes.

This video explores the GPT-2 paper "Language Models are Unsupervised Multitask Learners". The paper has this title because their experiments show how massive language models trained on massive datasets can perform tasks like Question Answering and Translation by carefully formatting them as language modeling inputs.
Paper Links
GPT-2 Paper: https://cdn.openai.com/better-....language-models/lang
AllenNLP GPT-2 Demo: https://demo.allennlp.org/next....-token-lm?text=Joel%
The Illustrated GPT-2: http://jalammar.github.io/illustrated-gpt2/
Combining GPT2 and BERT to make a fake person: https://www.bonkerfield.org/20....20/02/combining-gpt-
Thanks for watching! Please Subscribe!
고려대학교 산업경영공학과 일반대학원
Unstructured Data Analysis
08-4: GPT
Generative Pre-Trained Word Vectors, Transformer Decoder
https://github.com/pilsung-kang/text-analytics

How do you represent a word in AI? Rob Miles reveals how words can be formed from multi-dimensional vectors - with some unexpected results.
08:06 - Yes, it's a rubber egg :)
Unicorn AI:
EXTRA BITS: https://youtu.be/usthqKtw2LA
AI YouTube Comments: https://youtu.be/XyMdpcAPnZc
More from Rob Miles: http://bit.ly/Rob_Miles_YouTube
Thanks to Nottingham Hackspace for providing the filming location: http://bit.ly/notthack
https://www.facebook.com/computerphile
https://twitter.com/computer_phile
This video was filmed and edited by Sean Riley.
Computer Science at the University of Nottingham: https://bit.ly/nottscomputer
Computerphile is a sister project to Brady Haran's Numberphile. More at http://www.bradyharan.com

#ai #technology #switchtransformer
Scale is the next frontier for AI. Google Brain uses sparsity and hard routing to massively increase a model's parameters, while keeping the FLOPs per forward pass constant. The Switch Transformer compares favorably to its dense counterparts in terms of speed and sample efficiency and breaks the next magic number: One Trillion Parameters.
OUTLINE:
0:00 - Intro & Overview
4:30 - Performance Gains from Scale
8:30 - Switch Transformer Architecture
17:00 - Model-, Data- and Expert-Parallelism
25:30 - Experimental Results
29:00 - Stabilizing Training
32:20 - Distillation into Dense Models
33:30 - Final Comments
Paper: https://arxiv.org/abs/2101.03961
Codebase T5: https://github.com/google-rese....arch/text-to-text-tr
Abstract:
In deep learning, models typically reuse the same parameters for all inputs. Mixture of Experts (MoE) defies this and instead selects different parameters for each incoming example. The result is a sparsely-activated model -- with outrageous numbers of parameters -- but a constant computational cost. However, despite several notable successes of MoE, widespread adoption has been hindered by complexity, communication costs and training instability -- we address these with the Switch Transformer. We simplify the MoE routing algorithm and design intuitive improved models with reduced communication and computational costs. Our proposed training techniques help wrangle the instabilities and we show large sparse models may be trained, for the first time, with lower precision (bfloat16) formats. We design models based off T5-Base and T5-Large to obtain up to 7x increases in pre-training speed with the same computational resources. These improvements extend into multilingual settings where we measure gains over the mT5-Base version across all 101 languages. Finally, we advance the current scale of language models by pre-training up to trillion parameter models on the "Colossal Clean Crawled Corpus" and achieve a 4x speedup over the T5-XXL model.
Authors: William Fedus, Barret Zoph, Noam Shazeer
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yannic-kilcher
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ya....nnic-kilcher-4885341
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n

Meta AI’s recently shared Open Pretrained Transformer (OPT-175B), a language model with 175 billion parameters trained on publicly available data sets.
For the first time for a language technology system of this size, the release includes both the pretrained models and the code needed to train and use them.
This video contains three parts:
00:00 Quick Intro about OPT-175B
03:51 OPT-175B Live Demo with Alpa
08:07 OPT1.3B Text Generation Hands-on Coding using Hugging Face Transformers
Colab OPT1.3B Text Generation Tutorial - https://colab.research.google.....com/drive/1ZGfFzL9au
OPT-175B Blog post from Meta AI - https://ai.facebook.com/blog/d....emocratizing-access-
OPT-175B Live Demo - https://opt.alpa.ai/

It's the Github Copilot that you have at home ;) GPyT is a GPT style model that is trained from publicly accessible code on Github. You can get the model from here: https://huggingface.co/Sentdex/GPyT
Code samples used in the video: https://pythonprogramming.net/....GPT-python-code-tran
Neural Networks from Scratch book: https://nnfs.io
Channel membership: https://www.youtube.com/channe....l/UCfzlCWGWYyIQ0aLC5
Discord: https://discord.gg/sentdex
Reddit: https://www.reddit.com/r/sentdex/
Support the content: https://pythonprogramming.net/support-donate/
Twitter: https://twitter.com/sentdex
Instagram: https://instagram.com/sentdex
Facebook: https://www.facebook.com/pythonprogramming.net/
Twitch: https://www.twitch.tv/sentdex
Fine-tuning larger models can be tricky on consumer hardware. In this video I go over why its better to use large models for fine-tuning vs smaller models, I go over the issue with the naive approach to fine-tuning, and finally, I go over how to use DeepSpeed to successfully fine-tune even the largest GPT Neo model.
Notebook Git repo: https://github.com/mallorbc/GP....T_Neo_fine-tuning_no
finetuning repo: https://github.com/Xirider/finetune-gpt2xl
DeepSpeed repo: https://github.com/microsoft/DeepSpeed
happy transformers: https://happytransformer.com/
GPT article with images: https://towardsdatascience.com..../gpt-3-the-new-might
Timestamps
00:00 - Intro
00:36 - Background on fine-tuning
02:41 - Setting up Jupyter
05:17 - Incorrect naive fine-tuning method
10:02 - Correctly fine-tuning with DeepSpeed
15:35 - Fine-tuning the 2.7B model
16:35 - Fine-tuning the 1.3B model
17:55 - Looking at the README
20:08 - Outro and future work

Lex Fridman Podcast full episode: https://www.youtube.com/watch?v=rIpUf-Vy2JA
Please support this podcast by checking out our sponsors:
- Coinbase: https://coinbase.com/lex to get $5 in free Bitcoin
- Codecademy: https://codecademy.com and use code LEX to get 15% off
- Linode: https://linode.com/lex to get $100 free credit
- NetSuite: http://netsuite.com/lex to get free product tour
- ExpressVPN: https://expressvpn.com/lexpod and use code LexPod to get 3 months free
GUEST BIO:
Joscha Bach is a cognitive scientist, AI researcher, and philosopher.
PODCAST INFO:
Podcast website: https://lexfridman.com/podcast
Apple Podcasts: https://apple.co/2lwqZIr
Spotify: https://spoti.fi/2nEwCF8
RSS: https://lexfridman.com/feed/podcast/
Full episodes playlist: https://www.youtube.com/playli....st?list=PLrAXtmErZgO
Clips playlist: https://www.youtube.com/playli....st?list=PLrAXtmErZgO
SOCIAL:
- Twitter: https://twitter.com/lexfridman
- LinkedIn: https://www.linkedin.com/in/lexfridman
- Facebook: https://www.facebook.com/lexfridman
- Instagram: https://www.instagram.com/lexfridman
- Medium: https://medium.com/@lexfridman
- Reddit: https://reddit.com/r/lexfridman
- Support on Patreon: https://www.patreon.com/lexfridman

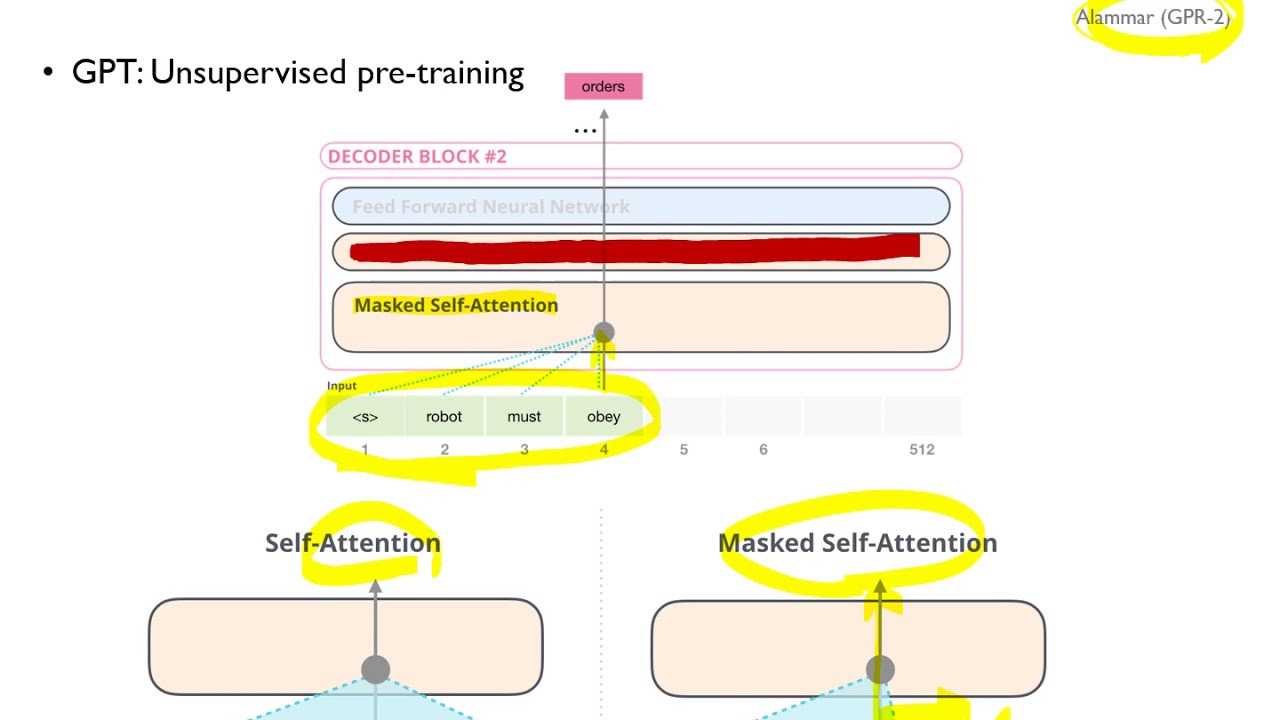
GPT is the first of the papers which proved the effectiveness of unsupervised pre-training for language processing tasks. This video is about GPT-1 which became quite an impactful work in the series of GPT papers that we now have (GPT-2 and GPT-3).
Paper: https://www.cs.ubc.ca/~amuham0....1/LING530/papers/rad
code: https://github.com/openai/finetune-transformer-l
Official OpenAI blog: https://openai.com/blog/language-unsupervised/
Paper Abstract:
Natural language understanding comprises a wide range of diverse tasks suchas textual entailment, question answering, semantic similarity assessment, anddocument classification. Although large unlabeled text corpora are abundant,labeled data for learning these specific tasks is scarce, making it challenging fordiscriminatively trained models to perform adequately. We demonstrate that largegains on these tasks can be realized bygenerative pre-trainingof a language modelon a diverse corpus of unlabeled text, followed bydiscriminative fine-tuningon eachspecific task. In contrast to previous approaches, we make use of task-aware inputtransformations during fine-tuning to achieve effective transfer while requiringminimal changes to the model architecture. We demonstrate the effectiveness ofour approach on a wide range of benchmarks for natural language understanding.Our general task-agnostic model outperforms discriminatively trained models thatuse architectures specifically crafted for each task, significantly improving upon thestate of the art in 9 out of the 12 tasks studied. For instance, we achieve absoluteimprovements of 8.9% on commonsense reasoning (Stories Cloze Test), 5.7% onquestion answering (RACE), and 1.5% on textual entailment (MultiNLI).
AI Bites
YouTube: https://www.youtube.com/c/AIBites
Twitter: https://twitter.com/ai_bites
Patron: https://www.patreon.com/ai_bites
github: https://github.com/ai-bites
![[ML News] De-Biasing GPT-3 | RL cracks chip design | NetHack challenge | Open-Source GPT-J](https://i.ytimg.com/vi/Ihg4XDWOy68/maxresdefault.jpg)
OUTLINE:
0:00 - Intro
0:30 - Google RL creates next-gen TPUs
2:15 - Facebook launches NetHack challenge
3:50 - OpenAI mitigates bias by fine-tuning
9:05 - Google AI releases browseable reconstruction of human cortex
9:50 - GPT-J 6B Transformer in JAX
12:00 - Tensorflow launches Forum
13:50 - Text style transfer from a single word
15:45 - ALiEn artificial life simulator
My Video on Chip Placement: https://youtu.be/PDRtyrVskMU
References:
RL creates next-gen TPUs
https://www.nature.com/articles/s41586-021-03544-w
https://www.youtube.com/watch?v=PDRtyrVskMU
Facebook launches NetHack challenge
https://ai.facebook.com/blog/l....aunching-the-nethack
Mitigating bias by fine-tuning
https://openai.com/blog/improv....ing-language-model-b
Human Cortex 3D Reconstruction
https://ai.googleblog.com/2021..../06/a-browsable-peta
GPT-J: An open-source 6B transformer
https://arankomatsuzaki.wordpr....ess.com/2021/06/04/g
https://6b.eleuther.ai/
https://github.com/kingoflolz/....mesh-transformer-jax
Tensorflow launches "Forum"
https://discuss.tensorflow.org/
Text style transfer from single word
https://ai.facebook.com/blog/a....i-can-now-emulate-te
ALiEn Life Simulator
https://github.com/chrxh/alien
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yannic-kilcher
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n

Learn how to generate Blog Posts, content writing, Articles with AI - BLOOM Language Model - True Open Source Alternative of GPT-3. It's also free. Just with a click of button from Google Colab you can generate Ai generated Blog posts and Articles.
This is good for content marketers to leverage AI to scale content writing.
Colab Code used here - https://github.com/amrrs/ai-content-gen-with-bloom
#gpt3 #aicontent

Self-attention and the transformer architecture have broken many benchmarks and enabled widespread progress in NLP. However, at this point neither researchers nor companies in industry (with a few exceptions) have leveraged them in a time series context. This talk will explore both the barriers and promise of self-attention models and transfer learning in a time series context. The talk will also look into why time series tasks (forecasting/prediction) have not had their BERT/Imagenet moment and what can be done to enable transfer learning on temporal data. The extremely limited COVID-19 time series forecasting dataset will be used as an example for the need to address these limited data scenarios and enable effective few-shot/transfer learning more generally.
Isaac Godfried is a machine learning engineer at Monster focusing on the data and machine learning platform. Prior to his current position Isaac worked on machine learning problems in both retail and healthcare. He also has participated in many Kaggle competitions. Isaac’s main focus is to remove barriers related to the use of deep learning in industry. Specifically, this involves researching techniques like transfer and meta learning for data constrained scenarios, designing tools to effectively track and manage experiments, and creating frameworks to deploy models at scale. In his spare time Isaac also conducts research in AI for good causes like medicine and climate.
👩🏼🚀Weights and Biases:
We’re always free for academics and open source projects. Email [email protected] with any questions or feature suggestions.
- Blog: https://www.wandb.com/articles
- Gallery: See what you can create with W&B -https://app.wandb.ai/gallery
- Continue the conversation on our slack community - http://bit.ly/wandb-forum

In this video, Rasa Developer Advocate Rachael will talk about what GPT-3 is, what it can be used to do and some of its drawback and limitations.
- “Rasa Reading Group: GPT3 (Part 1)” https://youtu.be/I8IHla4cXHk
- "Rasa Reading Group: GPT3 (Part 2)" https://www.youtube.com/watch?v=9sL08TCh7T8
- “GPT-3: Careful First Impressions” by Vincent Warmerdam https://blog.rasa.com/gpt-3-ca....reful-first-impressi
If you want to reach out to us, feel free to leave a message at our community forum; https://forum.rasa.com/.
