Top videos



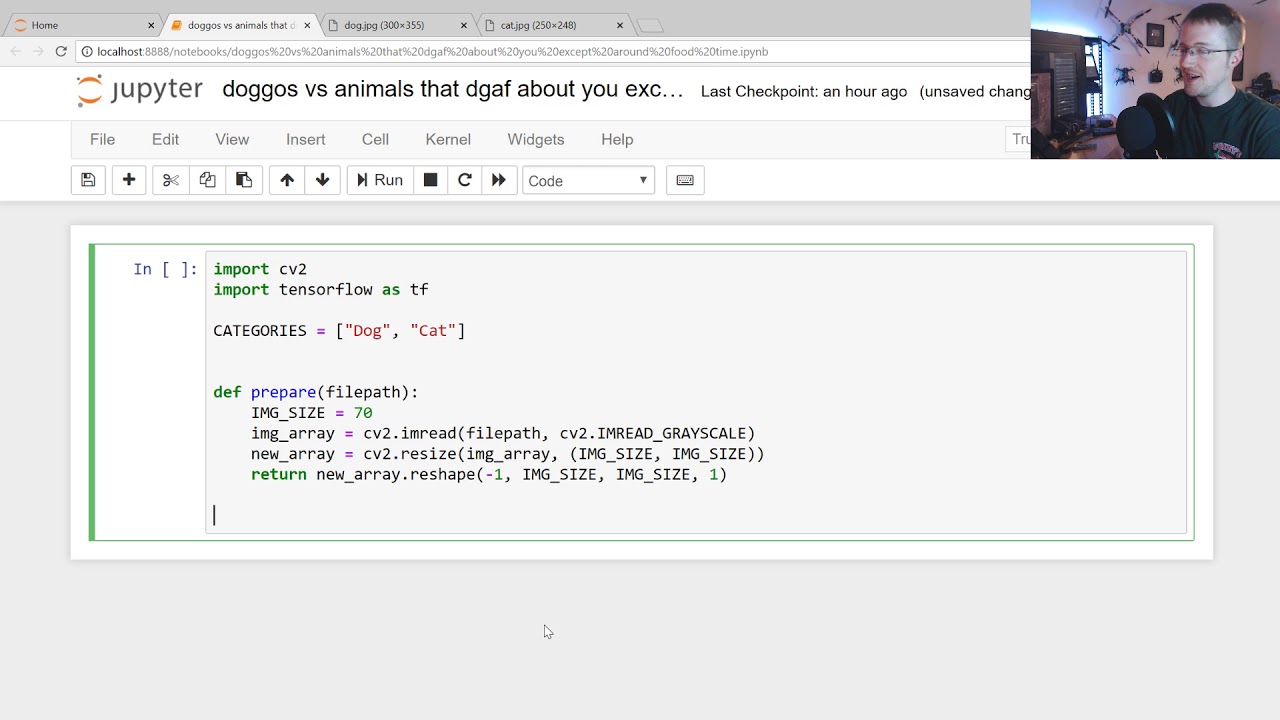
In this part, we're going to cover how to actually use your model. We will us our cats vs dogs neural network that we've been perfecting.
Text tutorial and sample code: https://pythonprogramming.net/....using-trained-model-
Dog example: https://pythonprogramming.net/....static/images/machin
Cat Example: https://pythonprogramming.net/....static/images/machin
Discord: https://discord.gg/sentdex
Support the content: https://pythonprogramming.net/support-donate/
Twitter: https://twitter.com/sentdex
Facebook: https://www.facebook.com/pythonprogramming.net/
Twitch: https://www.twitch.tv/sentdex
G+: https://plus.google.com/+sentdex

In this video we code the K-means clustering algorithm from scratch in the Python programming language. Below I link a few resources to learn more about K means clustering as well as to the Machine Learning Github repository where you can also find the code!
Resources to learn more about K means:
https://youtu.be/Ev8YbxPu_bQ (Watch the following lectures 13.2, 13.3, 13.4, 13.5 also)
http://cs229.stanford.edu/notes/cs229-notes7a.pdf
People often ask what courses are great for getting into ML/DL and the two I started with is ML and DL specialization both by Andrew Ng. Below you'll find both affiliate and non-affiliate links if you want to check it out. The pricing for you is the same but a small commission goes back to the channel if you buy it through the affiliate link.
ML Course (affiliate): https://bit.ly/3qq20Sx
DL Specialization (affiliate): https://bit.ly/30npNrw
ML Course (no affiliate): https://bit.ly/3t8JqA9
DL Specialization (no affiliate): https://bit.ly/3t8JqA9
GitHub Repository:
https://github.com/aladdinpers....son/Machine-Learning
✅ Equipment I use and recommend:
https://www.amazon.com/shop/aladdinpersson
❤️ Become a Channel Member:
https://www.youtube.com/channe....l/UCkzW5JSFwvKRjXABI
✅ One-Time Donations:
Paypal: https://bit.ly/3buoRYH
Ethereum: 0xc84008f43d2E0bC01d925CC35915CdE92c2e99dc
▶️ You Can Connect with me on:
Twitter - https://twitter.com/aladdinpersson
LinkedIn - https://www.linkedin.com/in/al....addin-persson-a95384
GitHub - https://github.com/aladdinpersson
PyTorch Playlist:
https://www.youtube.com/playli....st?list=PLhhyoLH6Ijf



Deep Learning libraries provide pre-written, professional-quality code that you can use for your own projects. Given the complexity of deep net applications, reusing code is a wise choice for a developer.
Deep Learning TV on
Facebook: https://www.facebook.com/DeepLearningTV/
Twitter: https://twitter.com/deeplearningtv
A library is a set of functions and modules that you can call through your own programs. Library code is typically created by highly-qualified software teams, and many libraries bring together large communities that support and extend the codebase. If you’re a developer, you’ve almost certainly used a library at one point in time.
For a commercial-grade deep learning application, the best libraries are deeplearning4j, Torch, and Caffe. The library Theano is suited for educational, research, and scientific projects. Other available libraries include Deepmat and Neon.
Have you ever tried to code your own deep net? Did you use a library to help simplify the process? Please comment and share your thoughts.
Credits
Nickey Pickorita (YouTube art) -
https://www.upwork.com/freelan....cers/~0147b8991909b2
Isabel Descutner (Voice) -
https://www.youtube.com/user/IsabelDescutner
Dan Partynski (Copy Editing) -
https://www.linkedin.com/in/danielpartynski
Marek Scibior (Prezi creator, Illustrator) -
http://brawuroweprezentacje.pl/
Jagannath Rajagopal (Creator, Producer and Director) -
https://ca.linkedin.com/in/jagannathrajagopal







Unstructured textual data is ubiquitous, but standard Natural Language Processing (NLP) techniques are often insufficient tools to properly analyze this data. Deep learning has the potential to improve these techniques and revolutionize the field of text analytics.
Deep Learning TV on
Facebook: https://www.facebook.com/DeepLearningTV/
Twitter: https://twitter.com/deeplearningtv
Some of the key tools of NLP are lemmatization, named entity recognition, POS tagging, syntactic parsing, fact extraction, sentiment analysis, and machine translation. NLP tools typically model the probability that a language component (such as a word, phrase, or fact) will occur in a specific context. An example is the trigram model, which estimates the likelihood that three words will occur in a corpus. While these models can be useful, they have some limitations. Language is subjective, and the same words can convey completely different meanings. Sometimes even synonyms can differ in their precise connotation. NLP applications require manual curation, and this labor contributes to variable quality and consistency.
Deep Learning can be used to overcome some of the limitations of NLP. Unlike traditional methods, Deep Learning does not use the components of natural language directly. Rather, a deep learning approach starts by intelligently mapping each language component to a vector. One particular way to vectorize a word is the “one-hot” representation. Each slot of the vector is a 0 or 1. However, one-hot vectors are extremely big. For example, the Google 1T corpus has a vocabulary with over 13 million words.
One-hot vectors are often used alongside methods that support dimensionality reduction like the continuous bag of words model (CBOW). The CBOW model attempts to predict some word “w” by examining the set of words that surround it. A shallow neural net of three layers can be used for this task, with the input layer containing one-hot vectors of the surrounding words, and the output layer firing the prediction of the target word.
The skip-gram model performs the reverse task by using the target to predict the surrounding words. In this case, the hidden layer will require fewer nodes since only the target node is used as input. Thus the activations of the hidden layer can be used as a substitute for the target word’s vector.
Two popular tools:
Word2Vec: https://code.google.com/archive/p/word2vec/
Glove: http://nlp.stanford.edu/projects/glove/
Word vectors can be used as inputs to a deep neural network in applications like syntactic parsing, machine translation, and sentiment analysis. Syntactic parsing can be performed with a recursive neural tensor network, or RNTN. An RNTN consists of a root node and two leaf nodes in a tree structure. Two words are placed into the net as input, with each leaf node receiving one word. The leaf nodes pass these to the root, which processes them and forms an intermediate parse. This process is repeated recursively until every word of the sentence has been input into the net. In practice, the recursion tends to be much more complicated since the RNTN will analyze all possible sub-parses, rather than just the next word in the sentence. As a result, the deep net would be able to analyze and score every possible syntactic parse.
Recurrent nets are a powerful tool for machine translation. These nets work by reading in a sequence of inputs along with a time delay, and producing a sequence of outputs. With enough training, these nets can learn the inherent syntactic and semantic relationships of corpora spanning several human languages. As a result, they can properly map a sequence of words in one language to the proper sequence in another language.
Richard Socher’s Ph.D. thesis included work on the sentiment analysis problem using an RNTN. He introduced the notion that sentiment, like syntax, is hierarchical in nature. This makes intuitive sense, since misplacing a single word can sometimes change the meaning of a sentence. Consider the following sentence, which has been adapted from his thesis:
“He turned around a team otherwise known for overall bad temperament”
In the above example, there are many words with negative sentiment, but the term “turned around” changes the entire sentiment of the sentence from negative to positive. A traditional sentiment analyzer would probably label the sentence as negative given the number of negative terms. However, a well-trained RNTN would be able to interpret the deep structure of the sentence and properly label it as positive.
Credits
Nickey Pickorita (YouTube art) -
https://www.upwork.com/freelan....cers/~0147b8991909b2
Isabel Descutner (Voice) -
https://www.youtube.com/user/IsabelDescutner
Dan Partynski (Copy Editing) -
https://www.linkedin.com/in/danielpartynski
Marek Scibior (Prezi creator, Illustrator) -
http://brawuroweprezentacje.pl/
Jagannath Rajagopal (Creator, Producer and Director) -
https://ca.linkedin.com/in/jagannathrajagopal

