Latest videos

Deep Learning Frameworks Machine Learning Libraries Artificial Intelligence Tutorial Data Science Projects AI with Python
Hi Guys,
In this short video, I talk about top 7 deep learning frameworks.
Thank you for watching. I hope you enjoy it.
Don't forget to subscribe and like the video.
Tirendaz Academy
#AI #MachineLearning #DeepLearning

When talking about artificial intelligence (AI), deep learning and machine learning are invariably mentioned in the same breath. But what do they mean? Are they same thing? Are they different? In this video, we explain what machine learning and deep learning mean, and how they fit into the AI family.
Did you know? you can start building A.I. applications for free on IBM Cloud
N.B. this IBM Cloud hyperlink should link to https://ibm.biz/whatisvideo
If you want to learn more, we've prepared loads of great resources to help you like:
- Tutorials
- Code Patterns
- Datasets
- Models
You can find these and more at http://ibm.biz/Bdqyv6
Build Smart. Build secure. Join a global community of developers at http://ibm.biz/IBMdeveloperYT
#IBMWhatIs
#AI
#MachineLearning
#DeepLearning
#Learn

If you are thinking about buying one... or two... GPUs for your deep learning computer, you must consider options like Ampere, GeForce, TITAN, and Quadro. These brands are rapidly evolving. In this video, I discuss this ever-changing landscape as of January 2021.
1:50 Cooling a GPU
2:40 Cooling 2 GPUs
3:10 NVLink
4:55 GPU Memory
7:00 NVIDIA GeForce 30 Series
8:26 Quadro
9:10 Multiple GPUs
14:14 More on NVLink
15:01 GPUs on Laptops
17:18 So what GPU would I get
Lenovo ThinkStation:
https://www.lenovo.com/us/en/t....hink-workstations/th
~~~~~~~~~~~~~~~ BUY A GPU ~~~~~~~~~~~~~~~~~~~~
NVIDIA 3090 GPU: https://amzn.to/3x6Kpph
NVIDIA 3080 GPU: https://amzn.to/3N6Z9tS
NVIDIA 3070 GPU: https://amzn.to/3m4v1mY
NVIDIA 3060 GPU: https://amzn.to/3x4allc
~~~~~~~~~~~~~~~ MY DEEP LEARNING COURSE ~~~~~~~~~~~~~~~
📖 Textbook - https://www.heatonresearch.com..../book/applications-d
😸🐙 GitHub - https://github.com/jeffheaton/....t81_558_deep_learnin
▶️ Play List - https://www.youtube.com/playli....st?list=PLjy4p-07OYz
🏫 WUSTL Course Site - https://sites.wustl.edu/jeffheaton/t81-558/
~~~~~~~~~~~~~~~ CONNECT ~~~~~~~~~~~~~~~
🖥️ Website: https://www.heatonresearch.com/
🐦 Twitter - https://twitter.com/jeffheaton
😸🐙 GitHub - https://github.com/jeffheaton
📸 Instagram - https://www.instagram.com/jeffheatondotcom/
🦾 Discord: https://discord.gg/3bjthYv
▶️ Subscribe: https://www.youtube.com/c/heat....onresearch?sub_confi
~~~~~~~~~~~~~~ SUPPORT ME 🙏~~~~~~~~~~~~~~
🅿 Patreon - https://www.patreon.com/jeffheaton
🙏 Other Ways to Support (some free) - https://www.heatonresearch.com/support.html
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#Python #Tensorflow #Keras

Reinforcement Learning has started to receive a lot of attention in the fields of Machine Learning and Data science. In January of 2016, a team of researchers from Google built an AI that beat the reigning world champion of the board game Go. This AI, AlphaGo, utilizes reinforcement learning in order to discover new strategies. Despite the potential of reinforcement learning, there are very few learning resources currently available. This video will help to demystify the field so that its capabilities can be better understood.
Deep Learning TV on
Facebook: https://www.facebook.com/DeepLearningTV/
Twitter: https://twitter.com/deeplearningtv
Relevant URLs
Richard Sutton book: https://webdocs.cs.ualberta.ca..../~sutton/book/ebook/
Tambet Matiisen post: https://www.nervanasys.com/dem....ystifying-deep-reinf
Andrej Karpathy post: http://karpathy.github.io/2016/05/31/rl/
Credits
Nickey Pickorita (YouTube art) -
https://www.upwork.com/freelan....cers/~0147b8991909b2
Isabel Descutner (Voice) -
https://www.youtube.com/user/IsabelDescutner
Dan Partynski (Copy Editing) -
https://www.linkedin.com/in/danielpartynski
Marek Scibior (Prezi creator, Illustrator) -
http://brawuroweprezentacje.pl/
Jagannath Rajagopal (Creator, Producer and Director) -
https://ca.linkedin.com/in/jagannathrajagopal

Caffe is a Deep Learning library that is well suited for machine vision and forecasting applications. With Caffe you can build a net with sophisticated configuration options, and you can access premade nets in an online community.
Deep Learning TV on
Facebook: https://www.facebook.com/DeepLearningTV/
Twitter: https://twitter.com/deeplearningtv
Caffe is a C++/CUDA library that was developed by Yangqing Jia of Google. The library was initially designed for machine vision tasks, but recent versions support sequences, speech and text, and reinforcement learning. Since it’s built on top of CUDA, Caffe supports the use of GPUs.
Caffe allows the user to configure the hyper-parameters of a deep net. The layer configuration options are robust and sophisticated – individual layers can be set up as vision layers, loss layers, activation layers, and many others. Caffe’s community website allows users to contribute premade deep nets along with other useful resources.
Vectorization is achieved through specialized arrays called “blobs”, which help optimize the computational costs of various operations.
Have you ever used the Caffe library in one of your Deep Net projects? Please comment and share your experiences.
Credits
Nickey Pickorita (YouTube art) -
https://www.upwork.com/freelan....cers/~0147b8991909b2
Isabel Descutner (Voice) -
https://www.youtube.com/user/IsabelDescutner
Dan Partynski (Copy Editing) -
https://www.linkedin.com/in/danielpartynski
Marek Scibior (Prezi creator, Illustrator) -
http://brawuroweprezentacje.pl/
Jagannath Rajagopal (Creator, Producer and Director) -
https://ca.linkedin.com/in/jagannathrajagopal

Autoencoders are a family of neural nets that are well suited for unsupervised learning, a method for detecting inherent patterns in a data set. These nets can also be used to label the resulting patterns.
Deep Learning TV on
Facebook: https://www.facebook.com/DeepLearningTV/
Twitter: https://twitter.com/deeplearningtv
Essentially, autoencoders reconstruct a data set and, in the process, figure out its inherent structure and extract its important features. An RBM is a type of autoencoder that we have previously discussed, but there are several others.
Autoencoders are typically shallow nets, the most common of which have one input layer, one hidden layer, and one output layer. Some nets, like the RBM, have only two layers instead of three. Input signals are encoded along the path to the hidden layer, and these same signals are decoded along the path to the output layer. Like the RBM, the autoencoder can be thought of as a 2-way translator.
Autoencoders are trained with backpropgation and a new concept known as loss. Loss measures the amount of information about the input that was lost through the encoding-decoding process. The lower the loss value, the stronger the net.
Some autoencoders have a very deep structure, with an equal number of layers for both encoding and decoding. A key application for deep autoencoders is dimensionality reduction. For example, these nets can transform a 256x256 pixel image into a representation with only 30 numbers. The image can then be reconstructed with the appropriate weights and bias; as an addition, some nets also add random noise at this stage in order to enhance the robustness of the discovered patterns. The reconstructed image wouldn’t be perfect, but the result would be a decent approximation depending on the strength of the net. The purpose of this compression is to the reduce the input size on a set of data before feeding it to a deep classifier. Smaller inputs lead to large computational speedups, so this preprocessing step is worth the effort.
Have you ever used an autoencoder to reduce the dimensionality of your data? Please comment and share your experiences.
Deep autoencoders are much more powerful than their predecessor, principal component analysis. In the video, you'll see the comparison of two letter codes associated with news stories of different topics. Among the two models, you’ll find the deep autoencoder to be far superior.
Credits
Nickey Pickorita (YouTube art) -
https://www.upwork.com/freelan....cers/~0147b8991909b2
Isabel Descutner (Voice) -
https://www.youtube.com/user/IsabelDescutner
Dan Partynski (Copy Editing) -
https://www.linkedin.com/in/danielpartynski
Marek Scibior (Prezi creator) -
http://brawuroweprezentacje.pl/
Jagannath Rajagopal (Creator, Producer and Director) -
https://ca.linkedin.com/in/jagannathrajagopal
Artificial neural networks provide us incredibly powerful tools in machine learning that are useful for a variety of tasks ranging from image classification to voice translation. So what is all the deep learning rage about? The media seems to be all over the newest neural network research of the DeepMind company that was recently acquired by Google. They used neural networks to create algorithms that are able to play Atari games, learn them like a human would, eventually achieving superhuman performance.
Deep learning means that we use artificial neural network with multiple layers, making it even more powerful for more difficult tasks. These machine learning techniques proved to be useful for many tasks beyond image recognition: they also excel at weather predictions, breast cancer cell mitosis detection, brain image segmentation and toxicity prediction among many others.
In this episode, an intuitive explanation is given to show the inner workings of deep learning algorithms.
________________________
Original blog post by Christopher Olah (source of many images):
http://colah.github.io/posts/2....014-03-NN-Manifolds-
You can train your own deep neural networks on Andrej Karpathy's website:
http://cs.stanford.edu/people/....karpathy/convnetjs/d
Images used in this video:
Bunny by Tomi Tapio K (CC BY 2.0) - https://flic.kr/p/8EbcEk
Train by B4bees (CC BY 2.0) - https://flic.kr/p/6RzHe4
Train with bunny by Alyssa L. Miller (CC BY 2.0) - https://flic.kr/p/5WPeRN
The knot theory blackboard image was created by Clayton Shonkwiler (CC BY 2.0) https://flic.kr/p/64FYv
The tangled knot image was created by Mikael Hvidtfeldt Christensen (CC BY 2.0) https://flic.kr/p/beYG9D
The thumbnail image is a work of Duncan Hull (CC BY 2.0) - https://flic.kr/p/98qtJB
Subscribe if you would like to see more of these! - http://www.youtube.com/subscri....ption_center?add_use
Splash screen/thumbnail design: Felícia Fehér - http://felicia.hu
Károly Zsolnai-Fehér's links:
Patreon → https://www.patreon.com/TwoMinutePapers
Facebook → https://www.facebook.com/TwoMinutePapers/
Twitter → https://twitter.com/karoly_zsolnai
Web → https://cg.tuwien.ac.at/~zsolnai/

Deep Nets come in a large variety of structures and sizes, so how do you decide which kind to use? The answer depends on whether you are classifying objects or extracting features. Let’s take a look at your choices.
Deep Learning TV on
Facebook: https://www.facebook.com/DeepLearningTV/
Twitter: https://twitter.com/deeplearningtv
A forewarning: this section contains several new terms, but rest assured – they will all be explained in the upcoming video clips.
If your goal is to train a classifier with a set of labelled data, you should use a Multilayer Perceptron (MLP) or a Deep Belief Network (DBN). Here are some guidelines if you are targeting any of the following applications:
- Natural Language Processing: use a Recursive Neural Tensor Network (RNTN) or Recurrent Net.
- Image Recognition: use a DBN or Convolutional Net
- Object Recognition: use a Convolutional Net or RNTN
- Speech Recognition: use a Recurrent Net
If your goal is to extract potentially useful patterns from a set of unlabelled data, you should use a Restricted Boltzmann Machine (RBM) or some other kind of autoencoder. For any work that involves the processing of time series data, use a Recurrent Net.
What deep nets do you see a use for? Please comment and let me know your thoughts.
Credits:
Nickey Pickorita (YouTube art) -
https://www.upwork.com/freelan....cers/~0147b8991909b2
Isabel Descutner (Voice) -
https://www.youtube.com/user/IsabelDescutner
Dan Partynski (Copy Editing) -
https://www.linkedin.com/in/danielpartynski
Marek Scibior (Prezi creator, Illustrator) -
http://brawuroweprezentacje.pl/
Jagannath Rajagopal (Creator, Producer and Director) -
https://ca.linkedin.com/in/jagannathrajagopal
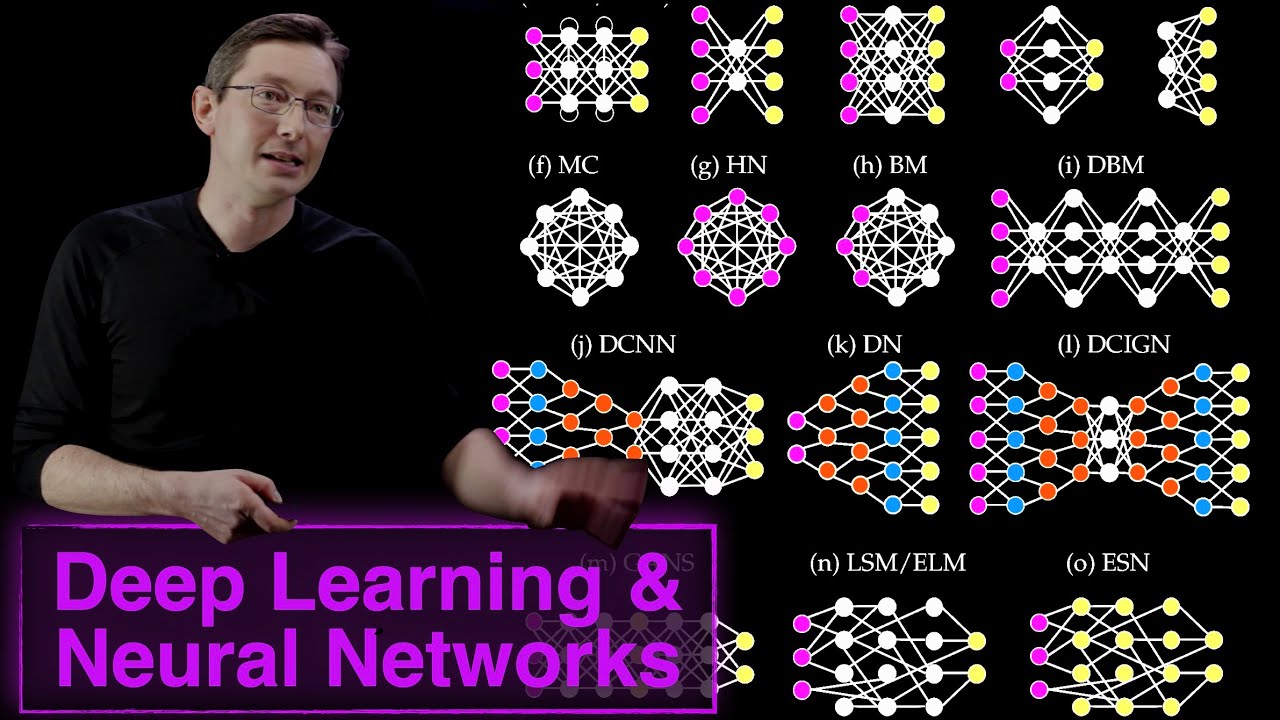
This video describes the variety of neural network architectures available to solve various problems in science ad engineering. Examples include convolutional neural networks (CNNs), recurrent neural networks (RNNs), and autoencoders.
Book website: http://databookuw.com/
Steve Brunton's website: eigensteve.com
Follow updates on Twitter @eigensteve
This video is part of a playlist "Intro to Data Science":
https://www.youtube.com/playli....st?list=PLMrJAkhIeNN

Training a large-scale deep net is a computationally expensive process, and common CPUs are generally insufficient for the task. GPUs are a great tool for speeding up training, but there are several other options available.
Deep Learning TV on
Facebook: https://www.facebook.com/DeepLearningTV/
Twitter: https://twitter.com/deeplearningtv
A CPU is a versatile tool than can be used across many domains of computation. However, the cost of this versatility is the dependence on sophisticated control mechanisms needed to manage the flow of tasks. CPUs also perform tasks serially, requiring the use of a limited number of cores in order to build in parallelism. Even though CPU speeds and memory limits have increased over the years, a CPU is still an impractical choice for training large deep nets.
Vector implementations can be used to speed up the deep net training process. Generally, parallelism comes in the form of both parallel processing and parallel programming. Parallel processing can either involve shared resources on a single computer, or distributed computing across a cluster of nodes.
The GPU is a common tool for parallel processing. As opposed to a CPU, GPUs tend to hold large numbers of cores – anywhere from 100s to even 1000s. Each of these cores is capable of general purpose computing, and the core structure allows for large amounts of parallelism. As a result, GPUs are a popular choice for training large deep nets. The Deep Learning community provides GPU support through various libraries, implementations, and a vibrant ecosystem fostered by nVidia. The main downside of a GPU is the amount of power required to run one relative to the alternatives.
The “Field Programmable Gate Array”, or FPGA, is another choice for training a deep net. FPGAs were originally used by electrical engineers to design mock-ups for different computer chips without having to custom build a chip for each solution. With an FPGA, chip function can be programmed at the lowest level – the logic gate. With this flexibility, an FPGA can be tailored for deep nets so as to require less power than a GPU. Aside from speeding up the training process, FPGAs can also be used to run the resultant models. For example, FPGAs would be useful for running a complex convolutional net over thousands of images every second. The downside of an FPGA is the specialized knowledge required during design, setup, and configuration.
Another option is the “Application Specific Integrated Circuit”, or ASIC. ASICs are highly specialized, with designs built in at the hardware and integrated circuit level. Once built, they will perform very well at the task they were designed for, but are generally unusable in any other task. Compared to GPUs and FPGAs, ASICs tend to have the lowest power consumption requirements. There are several Deep Learning ASICs such as the Google Tensor Processing Unit (TPU), and the chip being built by Nervana Systems.
There are a few parallelism options available with distributed computing such as data parallelism, model parallelism, and pipeline parallelism. With data parallelism, different subsets of the data are trained on different nodes in parallel for each training pass, followed by parameter averaging and replacement across the cluster. Libraries like TensorFlow support model parallelism, where different portions of the model are trained on different devices in parallel. With pipeline parallelism, workers are dedicated to tasks, like in an assembly line. The main idea is to ensure that each worker is relatively well-utilized. A worker starts the next job as soon as the current one is complete, a strategy that minimizes the total amount of wasted time.
Parallel programming research has been active for decades, and many advanced techniques have been developed. Generally, algorithms should be designed with parallelism in mind in order to take full advantage of the hardware. One such way to do this is to decompose the data model into independent chunks that each perform one instance of a task. Another option is to group all the tasks by their dependencies, so that each group is completely independent of the others. As an addition, you can implement threads or processes that handle different task groups. These threads can be used as a standalone solution, but will provide significant speed improvements when combined with the grouping method. To learn more about this topic, follow this link to the Open HPI Massive Open Online course (MOOC) on parallel programming - https://open.hpi.de/courses/parprog2014.
Credits
Nickey Pickorita (YouTube art) -
https://www.upwork.com/freelan....cers/~0147b8991909b2
Isabel Descutner (Voice) -
https://www.youtube.com/user/IsabelDescutner
Dan Partynski (Copy Editing) -
https://www.linkedin.com/in/danielpartynski
Marek Scibior (Prezi creator, Illustrator) -
http://brawuroweprezentacje.pl/
Jagannath Rajagopal (Creator, Producer and Director) -
https://ca.linkedin.com/in/jagannathrajagopal

If deep neural networks are so powerful, why aren’t they used more often? The reason is that they are very difficult to train due to an issue known as the vanishing gradient.
Deep Learning TV on
Facebook: https://www.facebook.com/DeepLearningTV/
Twitter: https://twitter.com/deeplearningtv
To train a neural network over a large set of labelled data, you must continuously compute the difference between the network’s predicted output and the actual output. This difference is called the cost, and the process for training a net is known as backpropagation, or backprop. During backprop, weights and biases are tweaked slightly until the lowest possible cost is achieved. An important aspect of this process is the gradient, which is a measure of how much the cost changes with respect to a change in a weight or bias value.
Backprop suffers from a fundamental problem known as the vanishing gradient. During training, the gradient decreases in value back through the net. Because higher gradient values lead to faster training, the layers closest to the input layer take the longest to train. Unfortunately, these initial layers are responsible for detecting the simple patterns in the data, while the later layers help to combine the simple patterns into complex patterns. Without properly detecting simple patterns, a deep net will not have the building blocks necessary to handle the complexity. This problem is the equivalent of to trying to build a house without the proper foundation.
Have you ever had this difficulty while using backpropagation? Please comment and let me know your thoughts.
So what causes the gradient to decay back through the net? Backprop, as the name suggests, requires the gradient to be calculated first at the output layer, then backwards across the net to the first hidden layer. Each time the gradient is calculated, the net must compute the product of all the previous gradients up to that point. Since all the gradients are fractions between 0 and 1 – and the product of fractions in this range results in a smaller fraction – the gradient continues to shrink.
For example, if the first two gradients are one fourth and one third, then the next gradient would be one fourth of one third, which is one twelfth. The following gradient would be one twelfth of one fourth, which is one forty-eighth, and so on. Since the layers near the input layer receive the smallest gradients, the net would take a very long time to train. As a subsequent result, the overall accuracy would suffer.
Credits
Nickey Pickorita (YouTube art) -
https://www.upwork.com/freelan....cers/~0147b8991909b2
Isabel Descutner (Voice) -
https://www.youtube.com/user/IsabelDescutner
Dan Partynski (Copy Editing) -
https://www.linkedin.com/in/danielpartynski
Jagannath Rajagopal (Creator, Producer and Director) -
https://ca.linkedin.com/in/jagannathrajagopal

With so many alternatives available, why are neural nets used for Deep Learning? Neural nets excel at complex pattern recognition and they can be trained quickly with GPUs.
Deep Learning TV on
Facebook: https://www.facebook.com/DeepLearningTV/
Twitter: https://twitter.com/deeplearningtv
Historically, computers have only been useful for tasks that we can explain with a detailed list of instructions. As such, they tend to fail in applications where the task at hand is fuzzy, such as recognizing patterns. Neural Networks fill this gap in our computational abilities by advancing machine perception – that is, they allow computers to start to making complex judgements about environmental inputs. Most of the recent hype in the field of AI has been due to progress in the application of deep neural networks.
Neural nets tend to be too computationally expensive for data with simple patterns; in such cases you should use a model like Logistic Regression or an SVM. As the pattern complexity increases, neural nets start to outperform other machine learning methods. At the highest levels of pattern complexity – high-resolution images for example – neural nets with a small number of layers will require a number of nodes that grows exponentially with the number of unique patterns. Even then, the net would likely take excessive time to train, or simply would fail to produce accurate results.
Have you ever had this problem in your own machine learning projects? Please comment.
As a result, deep nets are essentially the only practical choice for highly complex patterns such as the human face. The reason is that different parts of the net can detect simpler patterns and then combine them together to detect a more complex pattern. For example, a convolutional net can detect simple features like edges, which can be combined to form facial features like the nose and eyes, which are then combined to form a face (Credit: Andrew Ng). Deep nets can do this accurately – in fact, a deep net from Google beat a human for the first time at pattern recognition.
However, the strength of deep nets is coupled with an important cost – computational power. The resources required to effectively train a deep net were prohibitive in the early years of neural networks. However, thanks to advances in high-performance GPUs of the last decade, this is no longer an issue. Complex nets that once would have taken months to train, now only take days.
Credits:
Nickey Pickorita (YouTube art)
https://www.upwork.com/freelan....cers/~0147b8991909b2
Isabel Descutner (Voice) -
https://www.youtube.com/user/IsabelDescutner
Dan Partynski (Copy Editing) -
https://www.linkedin.com/in/danielpartynski
Jagannath Rajagopal (Creator, Producer and Director) -
https://ca.linkedin.com/in/jagannathrajagopal

So what was the breakthrough that allowed deep nets to combat the vanishing gradient problem? The answer has two parts, the first of which involves the RBM, an algorithm that can automatically detect the inherent patterns in data by reconstructing the input.
Deep Learning TV on
Facebook: https://www.facebook.com/DeepLearningTV/
Twitter: https://twitter.com/deeplearningtv
Geoff Hinton of the University of Toronto, a pioneer and giant in the field, was able to devise a method for training deep nets. His work led to the creation of the Restricted Boltzmann Machine, or RBM.
Structurally, an RBM is a shallow neural net with just two layers – the visible layer and the hidden layer. In this net, each node connects to every node in the adjacent layer. The “restriction” refers to the fact that no two nodes from the same layer share a connection.
The goal of an RBM is to recreate the inputs as accurately as possible. During a forward pass, the inputs are modified by weights and biases and are used to activate the hidden layer. In the next pass, the activations from the hidden layer are modified by weights and biases and sent back to the input layer for activation. At the input layer, the modified activations are viewed as an input reconstruction and compared to the original input. A measure called KL Divergence is used to analyze the accuracy of the net. The training process involves continuously tweaking the weights and biases during both passes until the input is as close as possible to the reconstruction.
If you’ve ever worked with an RBM in one of your own projects, please comment and tell me about your experiences.
Because RBMs try to reconstruct the input, the data does not have to be labelled. This is important for many real-world applications because most data sets – photos, videos, and sensor signals for example – are unlabelled. By reconstructing the input, the RBM must also decipher the building blocks and patterns that are inherent in the data. Hence the RBM belongs to a family of feature extractors known as auto-encoders.
Credits
Nickey Pickorita (YouTube art) -
https://www.upwork.com/freelan....cers/~0147b8991909b2
Isabel Descutner (Voice) -
https://www.youtube.com/user/IsabelDescutner
Dan Partynski (Copy Editing) -
https://www.linkedin.com/in/danielpartynski
Jagannath Rajagopal (Creator, Producer and Director) -
https://ca.linkedin.com/in/jagannathrajagopal

With plenty of machine learning tools currently available, why would you ever choose an artificial neural network over all the rest? This clip and the next could open your eyes to their awesome capabilities! You'll get a closer look at neural nets without any of the math or code - just what they are and how they work. Soon you'll understand why they are such a powerful tool!
Deep Learning TV on
Facebook: https://www.facebook.com/DeepLearningTV/
Twitter: https://twitter.com/deeplearningtv
Deep Learning is primarily about neural networks, where a network is an interconnected web of nodes and edges. Neural nets were designed to perform complex tasks, such as the task of placing objects into categories based on a few attributes. This process, known as classification, is the focus of our series.
Classification involves taking a set of objects and some data features that describe them, and placing them into categories. This is done by a classifier which takes the data features as input and assigns a value (typically between 0 and 1) to each object; this is called firing or activation; a high score means one class and a low score means another. There are many different types of classifiers such as Logistic Regression, Support Vector Machine (SVM), and Naïve Bayes. If you have used any of these tools before, which one is your favorite? Please comment.
Neural nets are highly structured networks, and have three kinds of layers - an input, an output, and so called hidden layers, which refer to any layers between the input and the output layers. Each node (also called a neuron) in the hidden and output layers has a classifier. The input neurons first receive the data features of the object. After processing the data, they send their output to the first hidden layer. The hidden layer processes this output and sends the results to the next hidden layer. This continues until the data reaches the final output layer, where the output value determines the object's classification. This entire process is known as Forward Propagation, or Forward prop. The scores at the output layer determine which class a set of inputs belongs to.
Links:
Michael Nielsen's book - http://neuralnetworksanddeeplearning.com/
Andrew Ng Machine Learning - https://www.coursera.org/learn/machine-learning
Andrew Ng Deep Learning - https://www.coursera.org/speci....alizations/deep-lear
Have you worked with neural nets before? If not, is this clear so far? Please comment.
Neural nets are sometimes called a Multilayer Perceptron or MLP. This is a little confusing since the perceptron refers to one of the original neural networks, which had limited activation capabilities. However, the term has stuck - your typical vanilla neural net is referred to as an MLP.
Before a neuron fires its output to the next neuron in the network, it must first process the input. To do so, it performs a basic calculation with the input and two other numbers, referred to as the weight and the bias. These two numbers are changed as the neural network is trained on a set of test samples. If the accuracy is low, the weight and bias numbers are tweaked slightly until the accuracy slowly improves. Once the neural network is properly trained, its accuracy can be as high as 95%.
Credits:
Nickey Pickorita (YouTube art) -
https://www.upwork.com/freelan....cers/~0147b8991909b2
Isabel Descutner (Voice) -
https://www.youtube.com/user/IsabelDescutner
Dan Partynski (Copy Editing) -
https://www.linkedin.com/in/danielpartynski
Jagannath Rajagopal (Creator, Producer and Director) -
https://ca.linkedin.com/in/jagannathrajagopal

An RBM can extract features and reconstruct input data, but it still lacks the ability to combat the vanishing gradient. However, through a clever combination of several stacked RBMs and a classifier, you can form a neural net that can solve the problem. This net is known as a Deep Belief Network.
Deep Learning TV on
Facebook: https://www.facebook.com/DeepLearningTV/
Twitter: https://twitter.com/deeplearningtv
The Deep Belief Network, or DBN, was also conceived by Geoff Hinton. These powerful nets are believed to be used by Google for their work on the image recognition problem. In terms of structure, a Deep Belief is identical to a Multilayer Perceptron, but structure is where their similarities end – a DBN has a radically different training method which allows it to tackle the vanishing gradient.
The method is known as Layer-wise, unsupervised, greedy pre-training. Essentially, the DBN is trained two layers at a time, and these two layers are treated like an RBM. Throughout the net, the hidden layer of an RBM acts as the input layer of the adjacent one. So the first RBM is trained, and its outputs are then used as inputs to the next RBM. This procedure is repeated until the output layer is reached.
Have you ever used this method to train a Deep Belief Network? Please comment and let me know your thoughts.
After this training process, the DBN is capable of recognizing the inherent patterns in the data. In other words, it’s a sophisticated, multilayer feature extractor. The unique aspect of this type of net is that each layer ends up learning the full input structure. In other types of deep nets, layers generally learn progressively complex patterns – for facial recognition, early layers could detect edges and later layers would combine them to form facial features. On the other hand, A DBN learns the hidden patterns globally, like a camera slowly bringing an image into focus.
In the end, a DBN still requires a set of labels to apply to the resulting patterns. As a final step, the DBN is fine-tuned with supervised learning and a small set of labeled examples. After making minor tweaks to the weights and biases, the net will achieve a slight increase in accuracy.
This entire process can be completed in a reasonable amount of time using GPUs, and the resulting net is typically very accurate. Thus the DBN is an effective solution to the vanishing gradient problem. As an added real-world bonus, the training process only requires a small set of labelled data.
Credits
Nickey Pickorita (YouTube art) -
https://www.upwork.com/freelan....cers/~0147b8991909b2
Isabel Descutner (Voice) -
https://www.youtube.com/user/IsabelDescutner
Dan Partynski (Copy Editing) -
https://www.linkedin.com/in/danielpartynski
Jagannath Rajagopal (Creator, Producer and Director) -
https://ca.linkedin.com/in/jagannathrajagopal

Deep Learning libraries provide pre-written, professional-quality code that you can use for your own projects. Given the complexity of deep net applications, reusing code is a wise choice for a developer.
Deep Learning TV on
Facebook: https://www.facebook.com/DeepLearningTV/
Twitter: https://twitter.com/deeplearningtv
A library is a set of functions and modules that you can call through your own programs. Library code is typically created by highly-qualified software teams, and many libraries bring together large communities that support and extend the codebase. If you’re a developer, you’ve almost certainly used a library at one point in time.
For a commercial-grade deep learning application, the best libraries are deeplearning4j, Torch, and Caffe. The library Theano is suited for educational, research, and scientific projects. Other available libraries include Deepmat and Neon.
Have you ever tried to code your own deep net? Did you use a library to help simplify the process? Please comment and share your thoughts.
Credits
Nickey Pickorita (YouTube art) -
https://www.upwork.com/freelan....cers/~0147b8991909b2
Isabel Descutner (Voice) -
https://www.youtube.com/user/IsabelDescutner
Dan Partynski (Copy Editing) -
https://www.linkedin.com/in/danielpartynski
Marek Scibior (Prezi creator, Illustrator) -
http://brawuroweprezentacje.pl/
Jagannath Rajagopal (Creator, Producer and Director) -
https://ca.linkedin.com/in/jagannathrajagopal
